Algorithm Comparison Matrix
Attribution Algorithm Comparison Matrix
Please, scroll to the right for more details.
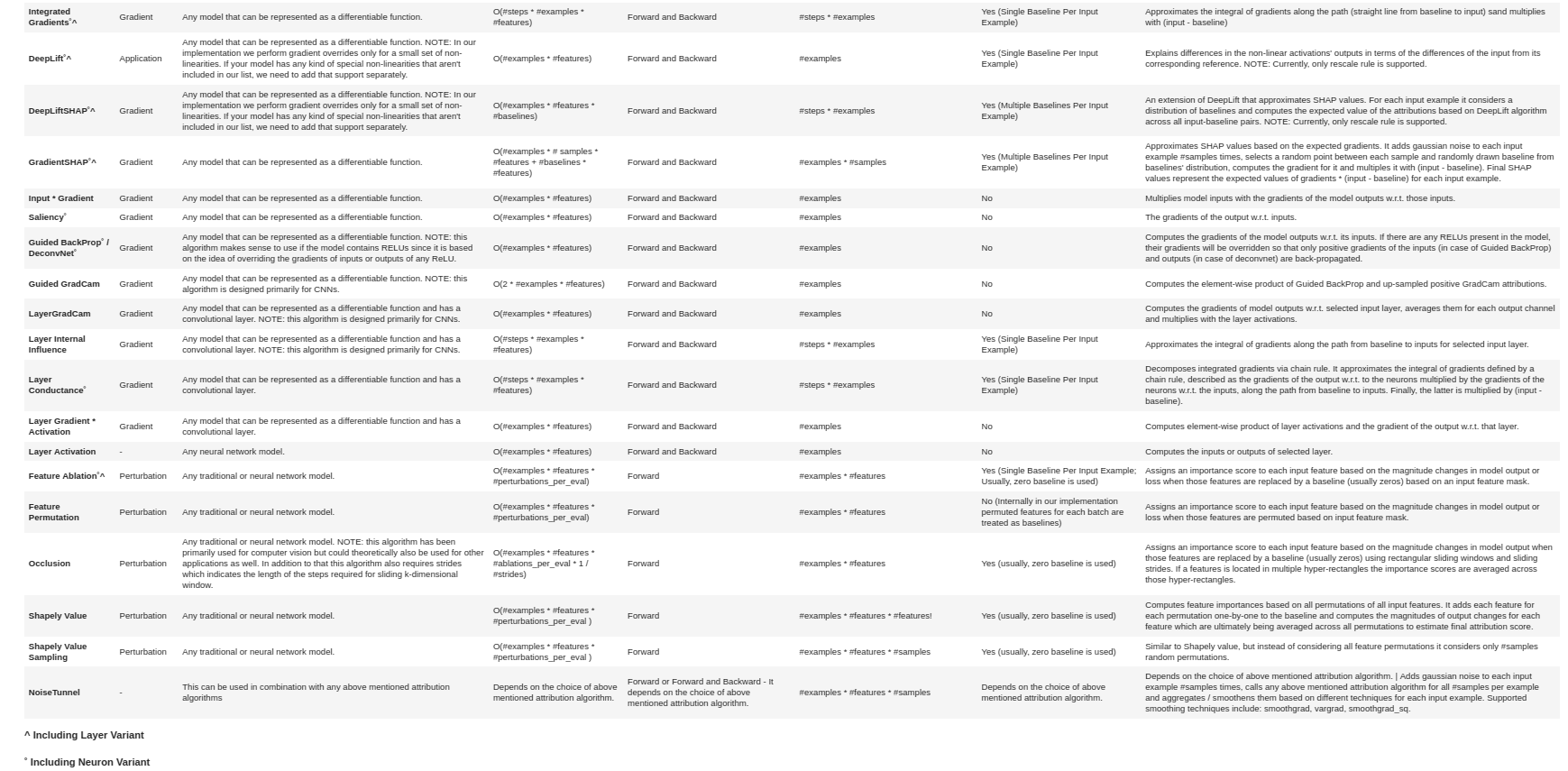
| Algorithm | Type | Application | Space Complexity | Model Passes (Forward Only or Forward and Backward)) | Number of Samples Passed through Model's Forward (and Backward) Passes | Requires Baseline aka Reference ? | Description |
|---|---|---|---|---|---|---|---|
| Integrated Gradients˚^ | Gradient | Any model that can be represented as a differentiable function. | O(#steps * #examples * #features) | Forward and Backward | #steps * #examples | Yes (Single Baseline Per Input Example) | Approximates the integral of gradients along the path (straight line from baseline to input) sand multiplies with (input - baseline) |
| DeepLift˚^ | Application | Any model that can be represented as a differentiable function. NOTE: In our implementation we perform gradient overrides only for a small set of non-linearities. If your model has any kind of special non-linearities that aren't included in our list, we need to add that support separately. | O(#examples * #features) | Forward and Backward | #examples | Yes (Single Baseline Per Input Example) | Explains differences in the non-linear activations' outputs in terms of the differences of the input from its corresponding reference. NOTE: Currently, only rescale rule is supported. |
| DeepLiftSHAP˚^ | Gradient | Any model that can be represented as a differentiable function. NOTE: In our implementation we perform gradient overrides only for a small set of non-linearities. If your model has any kind of special non-linearities that aren't included in our list, we need to add that support separately. | O(#examples * #features * #baselines) | Forward and Backward | #steps * #examples | Yes (Multiple Baselines Per Input Example) | An extension of DeepLift that approximates SHAP values. For each input example it considers a distribution of baselines and computes the expected value of the attributions based on DeepLift algorithm across all input-baseline pairs. NOTE: Currently, only rescale rule is supported. |
| GradientSHAP˚^ | Gradient | Any model that can be represented as a differentiable function. | O(#examples * # samples * #features + #baselines * #features) | Forward and Backward | #examples * #samples | Yes (Multiple Baselines Per Input Example) | Approximates SHAP values based on the expected gradients. It adds gaussian noise to each input example #samples times, selects a random point between each sample and randomly drawn baseline from baselines' distribution, computes the gradient for it and multiples it with (input - baseline). Final SHAP values represent the expected values of gradients * (input - baseline) for each input example. |
| Input * Gradient | Gradient | Any model that can be represented as a differentiable function. | O(#examples * #features) | Forward and Backward | #examples | No | Multiplies model inputs with the gradients of the model outputs w.r.t. those inputs. |
| Saliency˚ | Gradient | Any model that can be represented as a differentiable function. | O(#examples * #features) | Forward and Backward | #examples | No | The gradients of the output w.r.t. inputs. |
| Guided BackProp˚ / DeconvNet˚ | Gradient | Any model that can be represented as a differentiable function. NOTE: this algorithm makes sense to use if the model contains RELUs since it is based on the idea of overriding the gradients of inputs or outputs of any ReLU. | O(#examples * #features) | Forward and Backward | #examples | No | Computes the gradients of the model outputs w.r.t. its inputs. If there are any RELUs present in the model, their gradients will be overridden so that only positive gradients of the inputs (in case of Guided BackProp) and outputs (in case of deconvnet) are back-propagated. |
| Guided GradCam | Gradient | Any model that can be represented as a differentiable function. NOTE: this algorithm is designed primarily for CNNs. | O(2 * #examples * #features) | Forward and Backward | #examples | No | Computes the element-wise product of Guided BackProp and up-sampled positive GradCam attributions. |
| LayerGradCam | Gradient | Any model that can be represented as a differentiable function and has a convolutional layer. NOTE: this algorithm is designed primarily for CNNs. | O(#examples * #features) | Forward and Backward | #examples | No | Computes the gradients of model outputs w.r.t. selected input layer, averages them for each output channel and multiplies with the layer activations. |
| Layer Internal Influence | Gradient | Any model that can be represented as a differentiable function and has a convolutional layer. NOTE: this algorithm is designed primarily for CNNs. | O(#steps * #examples * #features) | Forward and Backward | #steps * #examples | Yes (Single Baseline Per Input Example) | Approximates the integral of gradients along the path from baseline to inputs for selected input layer. |
| Layer Conductance˚ | Gradient | Any model that can be represented as a differentiable function and has a convolutional layer. | O(#steps * #examples * #features) | Forward and Backward | #steps * #examples | Yes (Single Baseline Per Input Example) | Decomposes integrated gradients via chain rule. It approximates the integral of gradients defined by a chain rule, described as the gradients of the output w.r.t. to the neurons multiplied by the gradients of the neurons w.r.t. the inputs, along the path from baseline to inputs. Finally, the latter is multiplied by (input - baseline). |
| Layer Gradient * Activation | Gradient | Any model that can be represented as a differentiable function and has a convolutional layer. | O(#examples * #features) | Forward and Backward | #examples | No | Computes element-wise product of layer activations and the gradient of the output w.r.t. that layer. |
| Layer Activation | - | Any neural network model. | O(#examples * #features) | Forward and Backward | #examples | No | Computes the inputs or outputs of selected layer. |
| Feature Ablation˚^ | Perturbation | Any traditional or neural network model. | O(#examples * #features * #perturbations_per_eval) | Forward | #examples * #features | Yes (Single Baseline Per Input Example; Usually, zero baseline is used) | Assigns an importance score to each input feature based on the magnitude changes in model output or loss when those features are replaced by a baseline (usually zeros) based on an input feature mask. |
| Feature Permutation | Perturbation | Any traditional or neural network model. | O(#examples * #features * #perturbations_per_eval) | Forward | #examples * #features | No (Internally in our implementation permuted features for each batch are treated as baselines) | Assigns an importance score to each input feature based on the magnitude changes in model output or loss when those features are permuted based on input feature mask. |
| Occlusion | Perturbation | Any traditional or neural network model. NOTE: this algorithm has been primarily used for computer vision but could theoretically also be used for other applications as well. In addition to that this algorithm also requires strides which indicates the length of the steps required for sliding k-dimensional window. | O(#examples * #features * #ablations_per_eval * 1 / #strides) | Forward | #examples * #features | Yes (usually, zero baseline is used) | Assigns an importance score to each input feature based on the magnitude changes in model output when those features are replaced by a baseline (usually zeros) using rectangular sliding windows and sliding strides. If a features is located in multiple hyper-rectangles the importance scores are averaged across those hyper-rectangles. |
| Shapely Value | Perturbation | Any traditional or neural network model. | O(#examples * #features * #perturbations_per_eval ) | Forward | #examples * #features * #features! | Yes (usually, zero baseline is used) | Computes feature importances based on all permutations of all input features. It adds each feature for each permutation one-by-one to the baseline and computes the magnitudes of output changes for each feature which are ultimately being averaged across all permutations to estimate final attribution score. |
| Shapely Value Sampling | Perturbation | Any traditional or neural network model. | O(#examples * #features * #perturbations_per_eval ) | Forward | #examples * #features * #samples | Yes (usually, zero baseline is used) | Similar to Shapely value, but instead of considering all feature permutations it considers only #samples random permutations. |
| KernelSHAP / BaselineKernelShap | Perturbation | Any traditional or neural network model. | O(#examples * #features * #samples) | Forward | #examples * #samples | Yes (Single Baseline Per Input Example) | Uses the LIME framework with the Shapley kernel to estimate Baseline Shapley values. Missing features are replaced by the provided baseline values. |
| RandomBaselineKernelShap | Perturbation | Any traditional or neural network model. | O(#examples * #features * #samples * #baseline_samples) | Forward | #examples * #samples * #baseline_samples | Yes (Multiple Baselines Per Input Example) | Uses the same KernelSHAP surrogate as BaselineKernelShap, but averages each sampled coalition output over a baseline distribution before fitting the surrogate model. |
| NoiseTunnel | - | This can be used in combination with any above mentioned attribution algorithms | Depends on the choice of above mentioned attribution algorithm. | Forward or Forward and Backward - It depends on the choice of above mentioned attribution algorithm. | #examples * #features * #samples | Depends on the choice of above mentioned attribution algorithm. | Depends on the choice of above mentioned attribution algorithm. | Adds gaussian noise to each input example #samples times, calls any above mentioned attribution algorithm for all #samples per example and aggregates / smoothens them based on different techniques for each input example. Supported smoothing techniques include: smoothgrad, vargrad, smoothgrad_sq. |
^ Including Layer Variant
˚ Including Neuron Variant
{kind=link}